
머신 러닝이란?
다양한 정의가 있지만 가장 유명한 두 가지 정의로 설명하겠다.
Arthur Smuel(1959)
: 구체적인 프로그래밍 없이도 컴퓨터가 학습할 수 있는 능력을 주는 것을 연구하는 영역이다.
Tom Mitchell(1998)
: Well-posed learing problem : A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its peformance on T, improves with experience E.
머신러닝이란 어떤 과제를 수행하는 데에 있어서, 사람이 일일이 프로그래밍하는 것이 아닌 경험을 바탕으로 컴퓨터가 학습할 수 있는 능력을 말한다고 할 수있다.
정리하자면, 컴퓨터가 데이터를 바탕으로 과제를 수행할 수 있는 알고리즘을 만드는 것으로 이해 할 수 있다.
그렇다면 이런 머신러닝은 어떤 분야에서 적용될까?
머신러닝 적용 사례
- Data mining : 빅데이터에서 가치있는 정보를 찾아낸다.
예) 의료기록 데이터와 생물학과 공학등에서 지금까지 축적된 자료들로 분석할 수 있다.
web에서 사용자들의 click 정보를 분석하는 것등이 가능하다.
- Applications can't program by hand : 사람이 일일이 프로그램할 수 없는 것들에 사용된다.
예) 자동헬리콥터 조종기능, 손글씨 식별기능 , 자연어처리(NLP), computer vision등이 있다.
- Self-customizing programs : 사용자에게 맞춤형 서비스를 제공할 수 있다
예) Amazon, Netflix 등에서 자동 추천 시스템이 가능하다.
- Understanding human learning : 사람의 뇌를 연구하거나, 실제 사람과 비슷한 real AI를 연구할 수 있다.
Machine learing algorithms
알고리즘에는 크게 2가지가 있다.
- Supervised learning (지도 학습)
- Unsupervised learing (비지도 학습)
위의 두가지 말고도 reinforcement learing(강화 학습)이나 추천시스템 알고리즘 등이 있다.
Supervised Learning (지도학습)
Supervised learning 이란 데이터 값의 정답이나 실제 값을 함께 제공하고 을 학습시키는 것을 말한다.
- Regression(회귀)
- Classification(분류)
Ex 1 ) housing price prediction ( Regression )
집값을 예측해보자. y 축에는 가격이, x 축에는 집의 크기가 있다.
X 모양이 실제 데이터라고 할 때 우리는 데이터의 회귀모형을 이용해서 주어진 데이터의 정보가 아닌 새로운 데이터를 예측할 수 있다. 예로들어 "집 크기가 750일때 가격은 어떠할 것인가?" 를 예측 해볼 수 있다.
이때 사용하는 모델에 따라 예측의 정확도가 달라진다.
보라색 선은 선형 회귀(linear regression)를 이용했고, 파란색은 다항 회귀(polynomial regression)을 이용한 것이다.
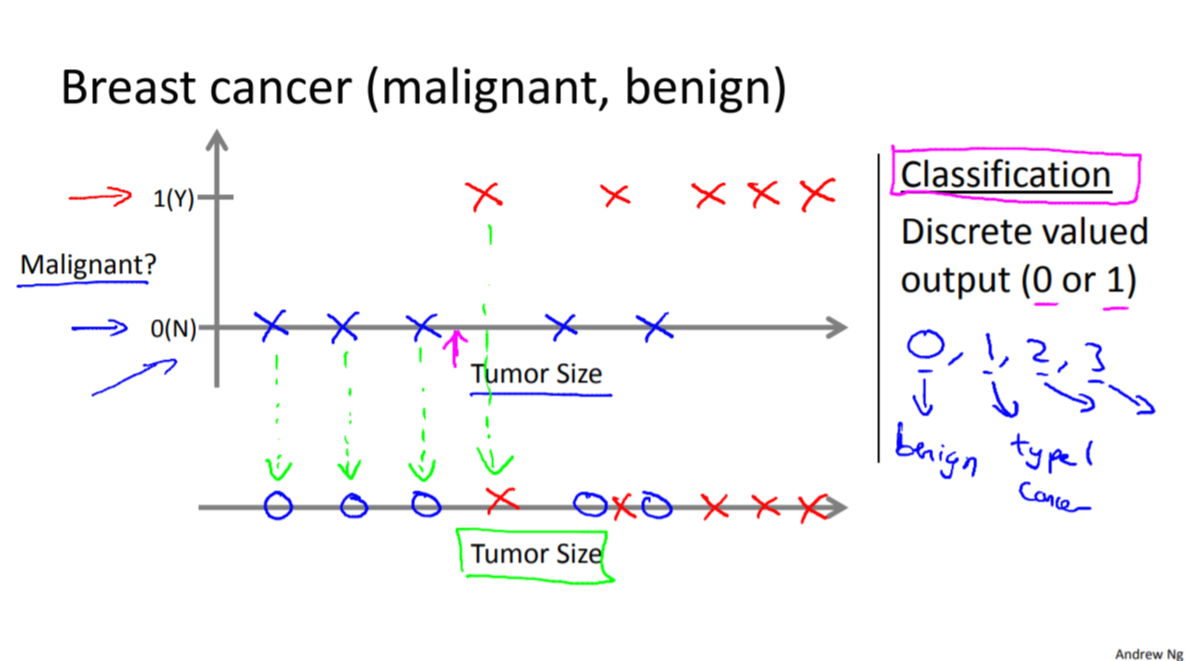
Ex 2 ) breast cancer 악성(malignant)인가 양성(benign) 인가? ( classification )
종양의 크기를 보고 악성인지 양성인지를 분류하는 곳에 머신러닝을 이용할 수 있다.
악성인 경우를 1 로 놓고, 양성인 경우를 0으로 놓고 분류할 수 있다.
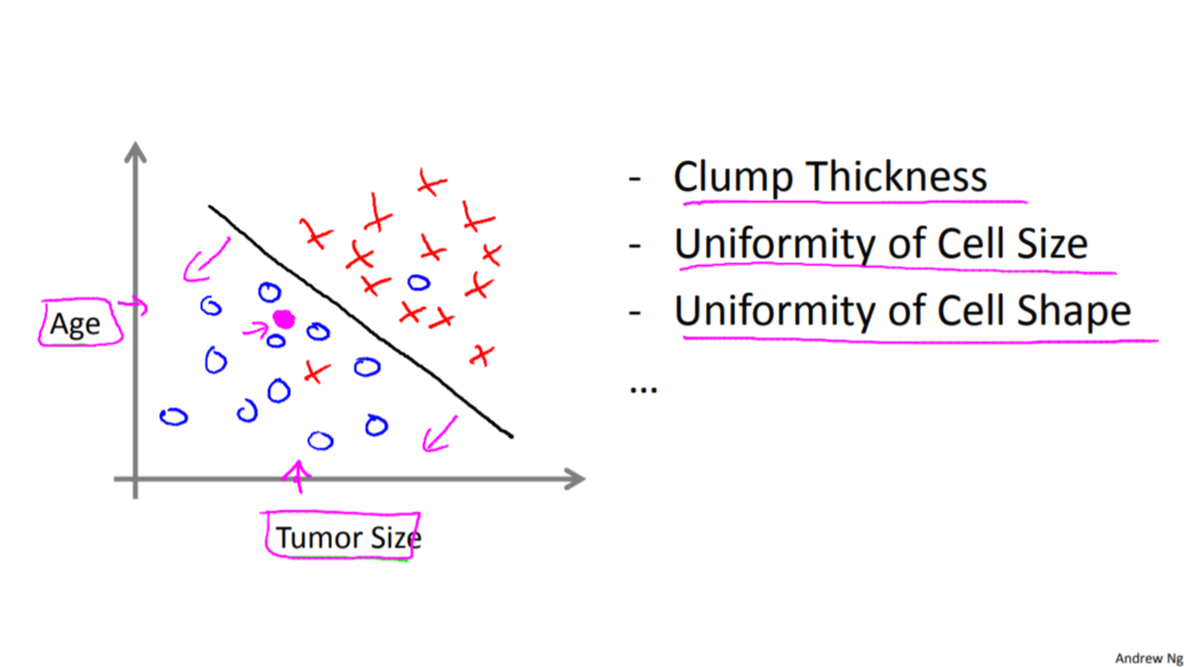
실제로는 Age, Clump Thickness, Uniformity of Cell Size, Uniformity of Cell Shape 등, 수만가지 특징(feature)을 가지고 분석할 것이다.
Unsuperviesd learning (비지도학습)
Unsupervised learning이란 지도학습과 달리 정답이 없이 데이터의 특징들끼리 비교하는 것이다. (Clustering)
Ex 1. google news (clustering)
같은 주제의 뉴스를 모아 준다. 하나의 주제에 여러 매체의 기사들을 군집화한다.
Ex 2. Market segmentation
Market segmentation이란 시장을 세분화 하는 것을 말한다. 비슷한 구매 성향과 특징을 가진 고객들끼리 세분화된 시장으로 나누어서 적절한 상품을 제시하는 것을 말한다.
위의 예들 말고도 대규모 컴퓨터 클러스터를 구성한다거나, Social network 분석, astronomical data 분석에서도 사용된다.
출처
Andrew Ng 교수님의 유투브 강의를 바탕으로 작성했습니다.
https://www.youtube.com/watch?v=PPLop4L2eGk
https://blog.martinwork.co.kr/ai/2018/07/08/what-is-machine-learning.html
'Artificial Intelligence > Basic' 카테고리의 다른 글
| A Beginner's Guide to Variational Methods: Mean-Field Approximation (0) | 2022.02.13 |
|---|---|
| 용어 정리 (인공지능, 머신러닝, 컴퓨터비전 분야) (0) | 2022.01.17 |
| Chapter 1 - 2 다층 신경망 (MLP; Multi-Layer Perceptrons) (0) | 2020.03.08 |
| Chapter 1 - 1 퍼셉트론(Perceptron), single layer (0) | 2020.03.06 |
| Mnist / Neural Net / Relu by jupyter (0) | 2020.03.05 |


