OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affinity Fields - 1
Key word : 2D human pose estimation, 2D foot keypoint estimation, real-time, multiple person, part affinity fields.
논문 출처 : CVPR_버전_2017, arxiv버전
이전글 : Human Pose Estimation 이란? (2022)
Human Pose Estimation 이란? (2022)
Human Pose Estimation Ultimate Overview in 2022 Human Pose Estimation with Deep Learning - Ultimate Overview in 2022 - viso.ai Pose Estimation is a computer vision technique to predict and track..
supermemi.tistory.com
목차
- 1. OpenPose 개요
- 2. Confidence Maps for Part Detection
- 3. Part Affinity Fields for Part Association\
- 4. Network Architecture and Training Details
1. OpenPose 개요
OpenPose 는 Bottom-up 기반의 2D Multi-person Pose Estimation Model 입니다.
Bottom-up 방식은 이미지 상에서 모든 신체 부위를 먼저 찾아내고, 이후에 찾아낸 신체 부위가 어떻게 연결되는지 추론 하는 방법을 말합니다. 여러 사람을 고려해야하는 multi-person pose estimation 의 경우, 이미지 상에 존재하는 모든 신체부위들 중 각 신체 부위가 누구의 것인지 알아내야 합니다.
Overal pipeline & Notations
자세한 내용은 글 뒤쪽에서 다룰 것이고, 이번 절에서는 간략하게 OpenPose model의 전체적인 흐름과 용어 표기에 대해서 먼저 알아 보겠습니다.

우리가 학습시키는 네트워크는 크게 두 가지 종류가 있습니다.
하나는 Part Confidence Maps 를 예측하고,
다른 하나는 Part Affinity Fields 를 예측합니다.
자세히 살펴보죠!
(a) Input Image
네트워크의 입력으로 컬러이미지가 들어옵니다.

(b) Part Confidence Maps
첫번째 네트워크는 입력 이미지에서 Confidence Maps 을 예측합니다.
confidence maps 은 신체 부위 별로 한장씩 존재하며, 하나의 confidence map 은 특정 신체 부위의 위치 정보를 담고 있습니다.
각 신체 부위는 하나의 값이 아닌 분포로 표현됩니다. 그래서 아래 사진을 보면 왼쪽 팔꿈치나 왼쪽 어깨를 하나의 좌표 값이 아닌 분포로 표현하고 있습니다.

예를들어 데이터 셋에서 신체 부위가 17개(ex. 왼쪽어깨, 왼쪽팔꿈치 ...)라고 하면, confidence map 또한 17개가 만들어집니다.
'왼쪽 팔꿈치'를 담당하는 confidence map 이라면 Fig. 2(b)의 왼쪽 예시처럼 '왼쪽 팔꿈치'만 높은 값을 가지게 됩니다.
반대로 '왼쪽 어깨'를 담당한다면 오른쪽 confidence map 예시처럼 나오겠지요.
모델은 multi-person 의 경우도 고려해야 하므로, 예시처럼 각 confidence map 에는 여러개의 peak 값들이 존재할 수 있습니다.
이러한 각 부위별 Confidence map 모두 모아서 집합 S 라고 정의합니다.

J 는 신체부위의 총 개수입니다.
소문자 j는 특정한 신체 부위를 나타냅니다.
(c) Part Affinity Fields (PAFs)
두번째 네트워크는 입력 이미지에서 Part Affinity Fields 를 예측합니다.
줄여서, PAFs 는 신체 부위 간 연관성 정보를 담고 있습니다.

limb : 두 신체 부위간 모든 연결 (두 관절을 연결한 뼈라고 생각하셔도 좋을 것 같아요)
Confidence map이 각 신체 부위별로 존재하는 것과 달리, PAFs 이러한 limb type 마다 존재합니다.
하나의 limb type 이란 예를들어, '왼쪽 어깨'와 '왼쪽 팔꿈치간'의 연결 하나를 의미합니다.
그렇다면 두 신체 부위간 연관성 정보를 어떻게 표현 할까요?
바로 2D Vector 값으로 표현합니다. 그래서 Fig2. (c)에서 보이는 것 처럼 화살표로 나타낼 수 있습니다.
따라서 PAFs 는 위치를 나타내는 location 정보와 방향을 나타내는 orientation 정보를 모두 가지고 있습니다.
multi-person 의 경우도 고려해야 하므로 하나의 PAF 에는 2D vector 값을 가지는 영역들이 여러개 존재할 수 있습니다.
이러한 PAFs 를 집합 L 이라고 정의합니다.
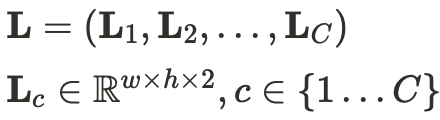
C 는 Limb type 의 총 개수를 의미합니다.
소문자 c 는 특정한 limb type 을 나타냅니다.
특정 limb에 속하는 각각의 pixel은 2D vector 로 표현합니다.
반대로, 특정 limb에 포함되지 않는 pixel은 0벡터 로 표현됩니다.
결론적으로, 특정 limb의 연관성을 표현하는 L_c 가 (w x h x 2) 의 크기를 가지는 것을 알 수 있습니다.
(d) Bipartite Matching
앞선 과정에서 우리의 모델은 Confidence maps 와 PAFs 를 예측했습니다.
이 두 예측 정보를 이용하여 우리는 신체 부위가 어떻게 연결되는지 찾아내야 합니다.
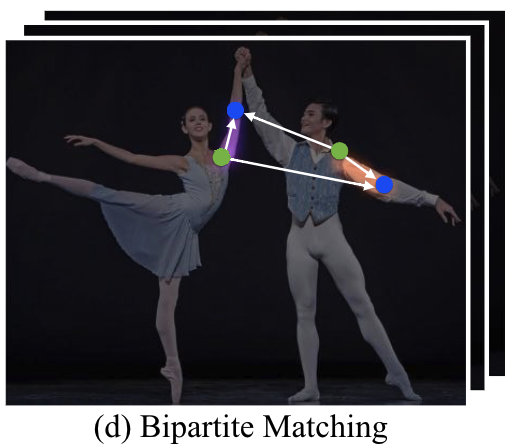
예를들어 Fig. 2d 에서 모델은 2개의 왼쪽 어깨(초록색 포인트)와 2개의 왼쪽 팔꿈치(파란색 포인트)를 검출했습니다.
다른 부위간 연결이 가능한 경우의 수는 총 4개(edge)입니다.
이들 중 가장 자연스러운 연결은 무엇일까요?
이때 우리는 앞에서 찾아낸 PAFs 정보를 이용할 수 있습니다. (어깨에서 팔꿈치로 향하는 2D vector)
Pair-wise association 점수가 가장 높은 연결을 선택하게 됩니다.
자세한건 글 뒤쪽에서 더 다루겠습니다.
(e) Parsing Results
각 부위별 Bipartite Matching의 결과들을 종합해서 연결하면 다음과 같이 multi-person full body poses를 구할 수 있습니다.

2. Confidence Maps for Part Detection
이제부터는 구체적으로 하나씩 확인해 봅시다!
먼저 Confidence map 입니다.
각 관절 type 마다 한장씩 존재합니다. 그 한장에는 여러 사람의 관절이 동시에 나타나게 됩니다.

학습 데이터 셋은 어떻게 구성되어 있을까요??
Input Data : Color image
Ground Truth : 각 관절의 위치를 나타내는 x,y 좌표 값
하지만, 우리의 관절은 하나의 점(pixel point)라기 보다는 영역(region)에 가깝지 않나요?
예를들어, 왼쪽 어깨를 나타내는 Ground truth point 가 (100,200)일때, 바로 옆 픽셀 (101,200)도 어깨라고 할 수 있습니다.
따라서 딥러닝 모델의 output이 pixel point가 아니라 confidence map이 되는 것이 좀 더 합리적인 추론이라고 생각할 수 있겠지요.
결론적으로, 네트워크 학습에 정답으로 사용되는 x,y 좌표를 모델 학습에 알맞게 변형할 필요가 있습니다.
How to Generate the Ground Truth confidence maps S* ?
2-1. 먼저, 이미지에 등장하는 각 사람객체마다 각 관절의 Ground truth Confidence map 을 만들어 줍니다.

j : 관절 유형
k : 특정 사람객체
즉, 하나의 이미지에 K명의 사람이 등장하는데 각 사람은 J개의 신체 부위를 가지고 있기 때문에 총 J*K 개의 ground truth confidence map 이 만들어져야 합니다. 그리고 이렇게 만들어진 map 에는 최대 1개의 peak값만 가지게 됩니다. 물론 이미지상에 그사람의 신체부위가 나타나지 않는다면 map은 모두 0으로 처리합니다.
구체적으로 Ground truth confidence map 을 구하는 식은 다음과 같습니다.
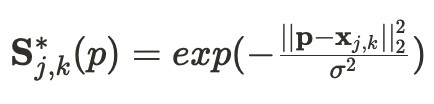

x 값은 쉽게 말해서 k번째 사람의 j번째 신체 부위의 Ground truth 좌표 값입니다.
이미지는 2차원이기 때문에 x 또한 2차원값으로 표현 됩니다.

시그마 값은 gt 좌표값에서 부터 얼마만큼 넓게 분포를 만들 것인가를 나타냅니다.
하나의 객체, 하나의 부위를 추출하는 것을 예시 코드로 간단하게 구현해 봤습니다.
정확하지 않을 수 있습니다...
[ 예시 코드 ]
import numpy as np
import matplotlib.pyplot as plt
def generate_S_j_k(img, gt, sigma):
a = np.arange(img.shape[0])
b = np.arange(img.shape[1])
ax,bx = np.meshgrid(a,b,indexing='ij')
p = np.stack((ax,bx),axis=-1)
S_j_k = np.exp(-np.linalg.norm(p-gt,ord=2,axis=-1)/(sigma**2))
return S_j_k
i = plt.imread('ex.jpeg')
x = np.array([200,500]) # (i,j) GT right-hair ground truth
sigma = 10
S_j_k = generate_S_j_k(i,x,sigma)
plt.imshow(i)
plt.imshow(S_j_k,cmap='jet',alpha=0.8)
plt.show()[ 예시 코드 결과 ]

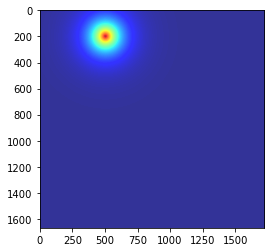

목표로 하는 매미의 오른쪽 더듬이 부분에 GT 분포가 잘 만들어진 것 같습니다...ㅎ
2-2. Ground truth Confidence map 를 관절 별로 통합합니다.
j : 관절 유형
k : 사람 객체
앞에서 각 사람(k)의 각 관절(j)에 대한 confidence map(S_j,k)을 구했다면
이번에는 각 관절(j)에 대한 confidence map(S_j)으로 통합합니다.
그결과, 각 관절의 confidence map(S_j)에는 사람들(k)의 각 관절(j)에 대한 정보가 모두 포함 될 겁니다.
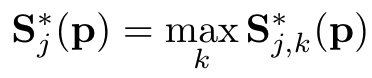
Max 를 사용하면 됩니다.
사람마다 이미지에서 동일한 관절의 위치가 다르기 때문에 높은 값(peak value)의 위치가 다른 위치에서 만들어집니다.
높은 값들을 모아서 하나의 map으로 통합하는 과정이라고 이해하시면 됩니다..
[예시 코드]
제가 구현해본 거라 정확하지 않을 수 있습니다...
import numpy as np
import matplotlib.pyplot as plt
i = plt.imread('cau.jpeg')
def generate_S_j_k(img, gt, sigma):
a = np.arange(img.shape[0])
b = np.arange(img.shape[1])
ax,bx = np.meshgrid(a,b,indexing='ij')
p = np.stack((ax,bx),axis=-1)
S_j_k = np.exp(-np.linalg.norm(p-gt,ord=2,axis=-1)/(sigma**2))
return S_j_k
def generate_S_j(img,gt,sigma):
S_j = []
for g,s in zip(gt,sigma):
S_j.append(generate_S_j_k(img,g,s))
S_j = np.max(S_j,axis=0)
return S_j
def show_confidence_map(confi_map,cmap,alpha):
plt.imshow(i)
plt.imshow(confi_map,cmap=cmap,alpha=alpha)
plt.show()
x = np.array([[325,390],[540,755]]) # GT right eye ground truth
sigma = np.array([7,5])
S_j_1 = generate_confidence_map_gt(i,x[0],sigma[0])
show_confidence_map(S_j_1,'jet',0.6)
S_j_2 = generate_confidence_map_gt(i,x[1],sigma[1])
show_confidence_map(S_j_2,'jet',0.6)
S_j = generate_S_j(i,x,sigma)
show_confidence_map(S_j,'jet',0.6)[데이터 : 푸앙이와 말랑이 인형이 나온 사진을 사용해 보죠]

[결과]



그런데 왜 Max 를 사용했을까요??
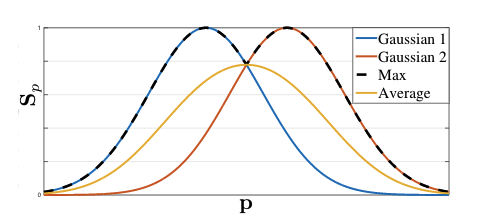
이유는 max가 각 peak값을 잘 표현하기 때문입니다.
예를들어 손을 잡고 있는 경우 사람1과 사람2의 손은 거의 비슷한 위치에 존재합니다.
이때, Average를 사용하여 통합하게 된다면 두 객체의 peak point가 보전되지 않고 이상한 중앙 위치에 하나만 만들어 지겠죠..
이러한 점을 방지하고 성능 향상을 위해 논문의 저자는 max를 사용하여 통합했다고 합니다.
2-3. 모델 네트워크에서는 Confidence map을 어떻게 처리할까요? (At test time)
지금까지는 학습 데이터의 Ground Truth 값을 어떻게 만드는지를 설명했습니다.
그렇다면 모델에서는 예측한 결과를 어떻게 처리할까요?
이미지를 입력으로 받아서, 모델 네트워크는 결과로 Confidence map을 예측합니다.
이때 나온 Confidence map은 확률값으로 나타나게 되는데 비슷한 위치에 여러개의 peak 값들이 존재할 수 있습니다.
예를들어 손을 탐지했는데, 모델이 손가락 엄지부위와 손바닥 부위를 높은 값으로 예측할 수 있지요.
또 손이 아닌 발을 손으로 탐지했을 수도 있겠지요. 이경우에는 confidence value 가 낮겠지요.
이렇게 다양한 탐지값을 내놓는 경우 Non-maximum suppression 알고리즘을 이용하여 제일 좋아보이는 것을 하나만 남기는 과정이 진행됩니다.
Object detection 에서도 많이 사용되는 방식입니다.
다음 글에서는 나머지 부분에 대해서 다뤄 보겠습니다.
OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affinity Fields - 2
OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affinity Fields - 2 OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affinity Fields - 1 OpenPose: Realtime Multi..
supermemi.tistory.com
- 3. Part Affinity Fieds for Part Association
- 4. Network Architecture and Training Details
'Artificial Intelligence > Paper Reviews' 카테고리의 다른 글
| [ 논문 리뷰 ] A Fourier-based Framework for Domain Generalization (1) | 2022.09.05 |
|---|---|
| [ 논문 리뷰 ] OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affinity Fields - 2 (0) | 2022.04.10 |

