Graph Machine Learning for Visual Computing (GML4VC) Tutorial

CVPR 2022 에서 Graph Machine Learning 에 대한 튜토리얼(tutorial)을 진행했습니다.
이에 대해 요약 정리 하는 시리즈 글입니다.
[이전 글]
2022.08.22 - [AI/Graph Neural Networks] - [ CVPR2022 / GML4VC ] 1. 개요 (Graph Machine Learning, GNNs)
2022.08.22 - [AI/Graph Neural Networks] - [ CVPR2022 / GML4VC ] 2. Open Remarks
2022.08.24 - [AI/Graph Neural Networks] - [ CVPR2022 / GML4VC ] 5. Pytorch Geometric 이란 무엇인가?
2022.08.25 - [AI/Graph Neural Networks] - [ CVPR2022 / GML4VC ] 6. Deep GNNs (심층 그래프 신경망) 기본 개념 정리
이전 글에 이어지는 내용입니다.
Graph ML for Video Understanding
- 동영상 링크 : video
- 발표자 : Bernard Ghanem
bernard_talk.mp4
drive.google.com


Video Understanding Tasks
- T1 : Temporal Activity Localization (TAL)
- T2 : Video Language Grounding (VLG)
- T3 : Active Speaker Detection (ASD)
T1 : Temporal Activity Localization (TAL)
Temporal 이란 시간 축 정도로 이해하시면 됩니다.
TAL 은 비디오 속에서 어떠한 행동이 언제 일어났는지를 알아내는 과제 입니다. 자세히 말하면, 비디오와 행동 클래스가 입력값으로 들어가면 출력값으로는 행동이 존재하는 비디오의 시작과 끝 시간(frame)이 됩니다.
즉, 시간 축으로 action detection을 하는 과제라고 생각하면 됩니다.

일반적으로 비디오는 짧은 길이의 Clip 의 모음으로 표현됩니다. 이 짧은 영상인 clip 을 학습하는 clip encoder가 존재합니다.

Clip encoder 를 통해 clip 들을 어떠한 Visual Representation 으로 변환할 수 있습니다.

일반적으로, 이렇게 clip 단위로 변환된 visual representation 을 가지고 action detection 을 진행하게 됩니다.
하지만 여기서 문제가 발생합니다. 비디오에서 어떠한 행동은 여러 clip들에 연속해서 진행될 수 있습니다. 다시말하면, long-term dependency가 존재한다는 것이죠. 그러나 위의 방법은 짧은 길이의 clip을 단위로 판단을 하기 때문에 앞뒤 clip 간 정보를 공유하지 않습니다.
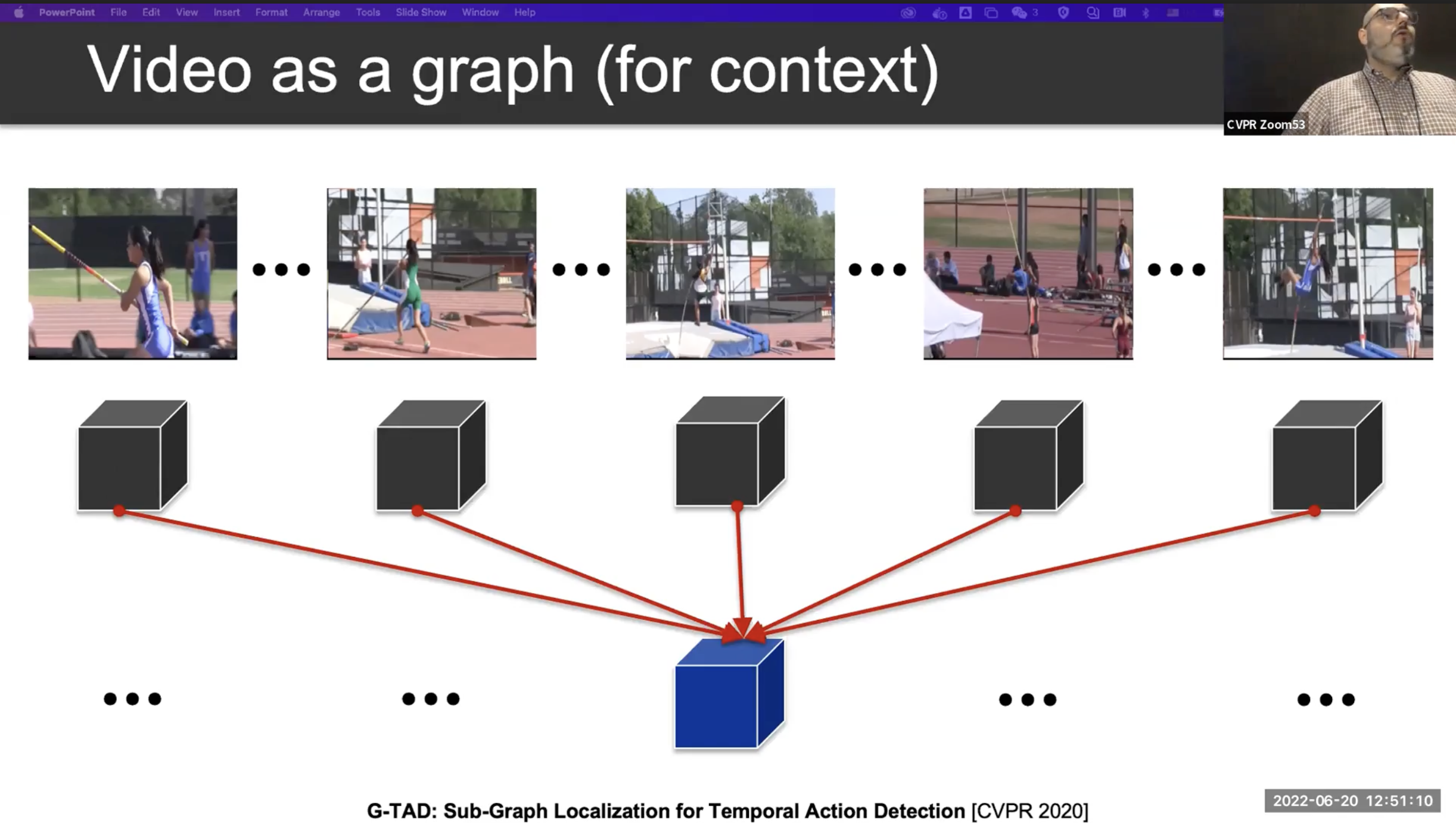
이러한 문제를 해결하는 하나의 방법으로, Video 를 graph 라고 생각해 볼 수 있습니다. 각 clip 의 visual representation 을 하나의 노드라고 생각하고, 이들을 연결한 노드를 통해서 clip간 정보를 통합 할 수 있습니다.
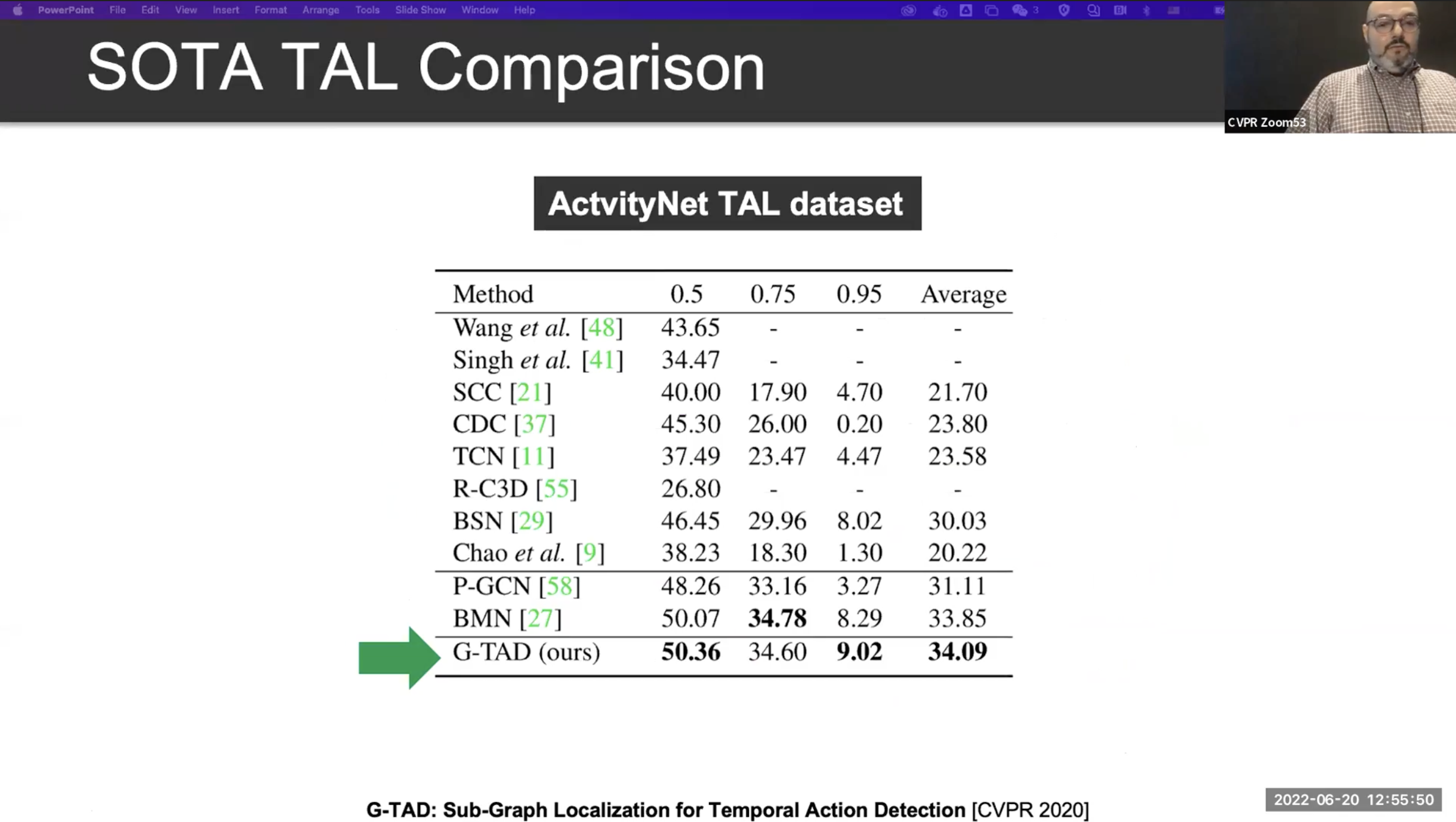
Graph-Based TAL
위의 내용을 정리한 그래프 기반의 TAL 모델을 자세히 보면, 시계 반대 방향으로 시간축을 형성하고 start node(Red), end node(Blue)를 잘 찾아내고 어떠한 행동인지를 분류하는 과제로 바뀝니다.
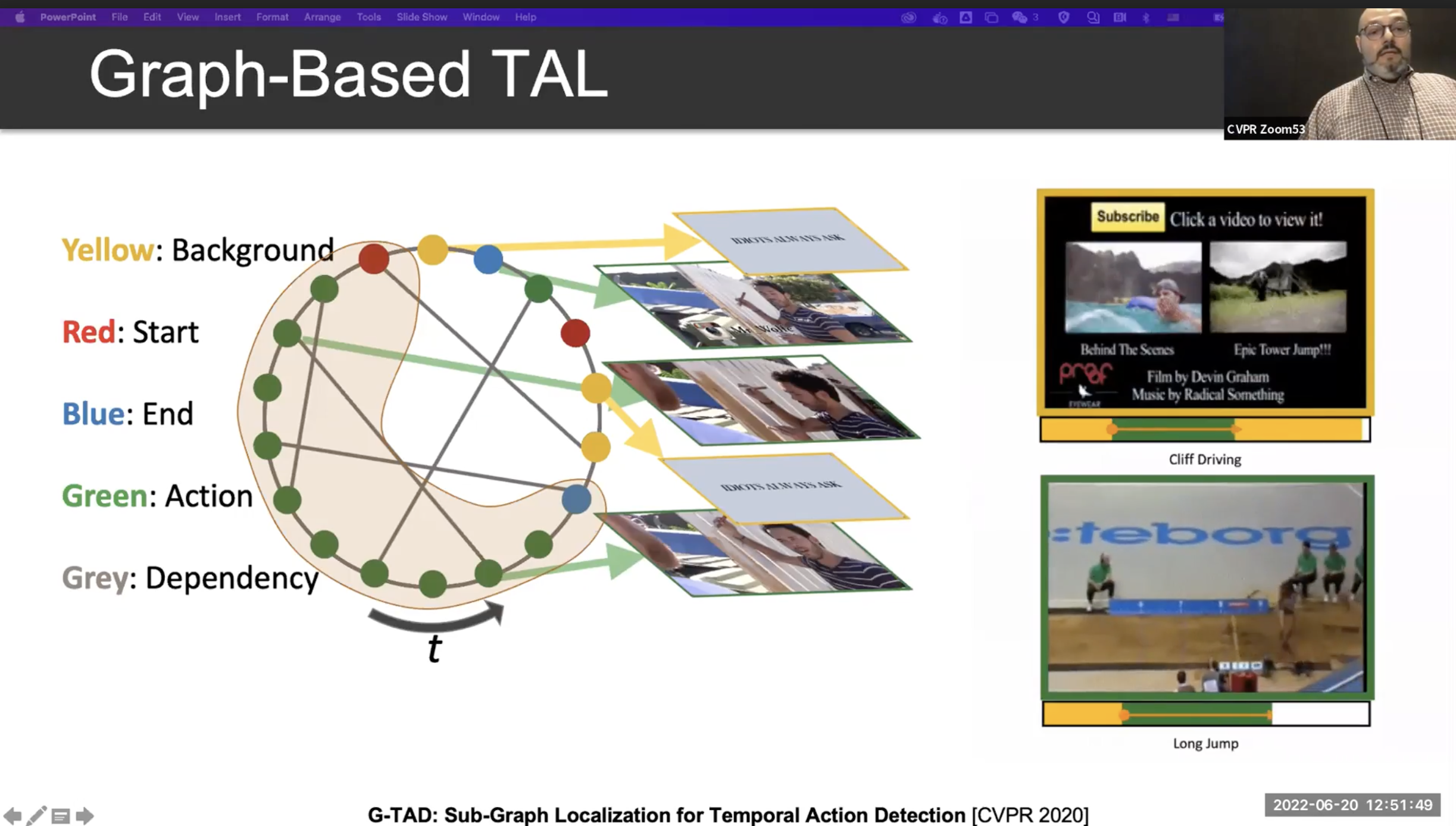
- 비디오를 짧은 영상 단위인 Clip 들로 나누어 줍니다.
- 각 clip을 graph node 라고 생각합니다.
- edge에는 두가지 종류가 있습니다.
- 하나는 Semantic Connection(Dynamic) 이며,
- 다른 하나는 Temporal Connection(Static) 입니다.
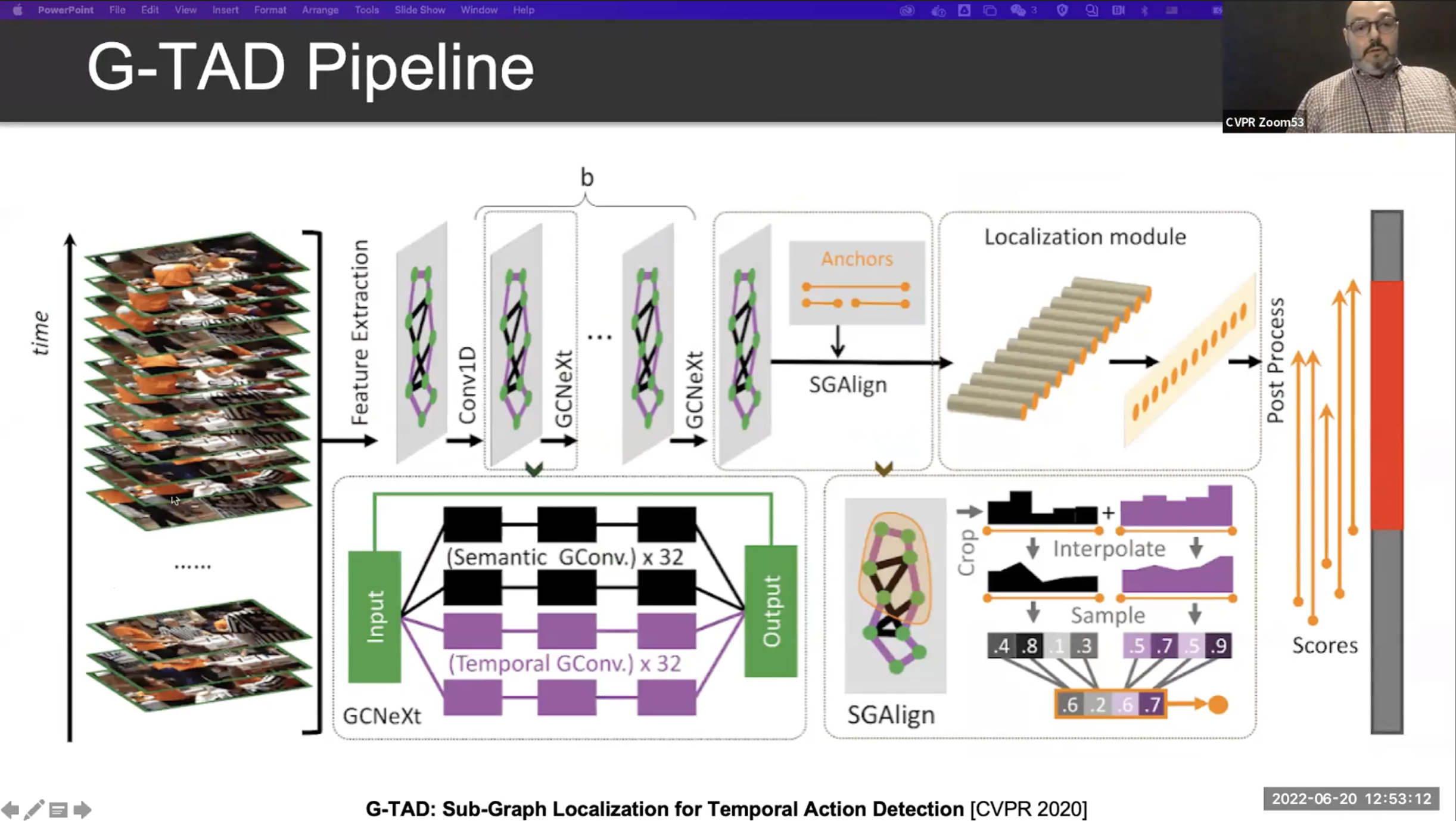
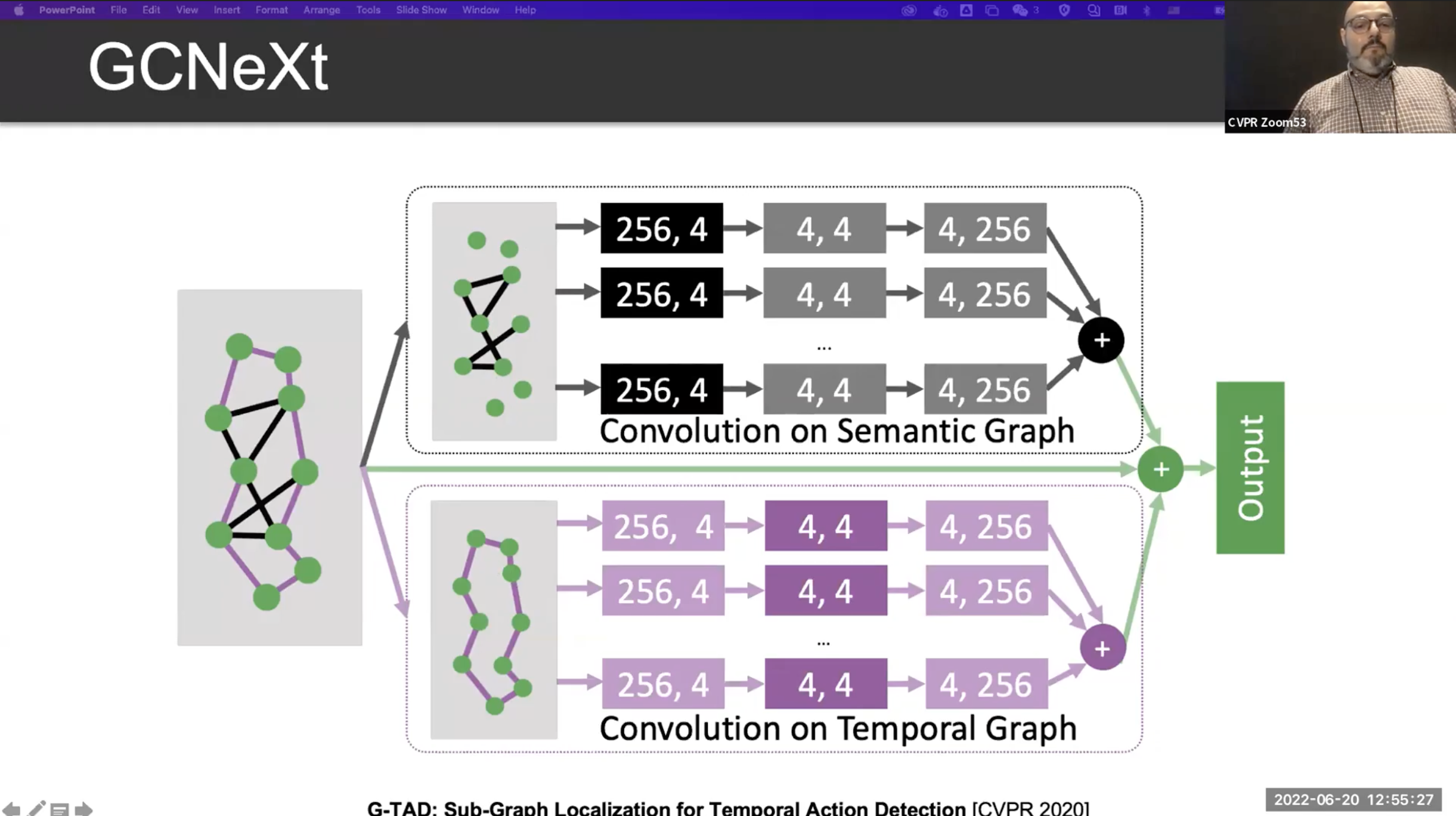
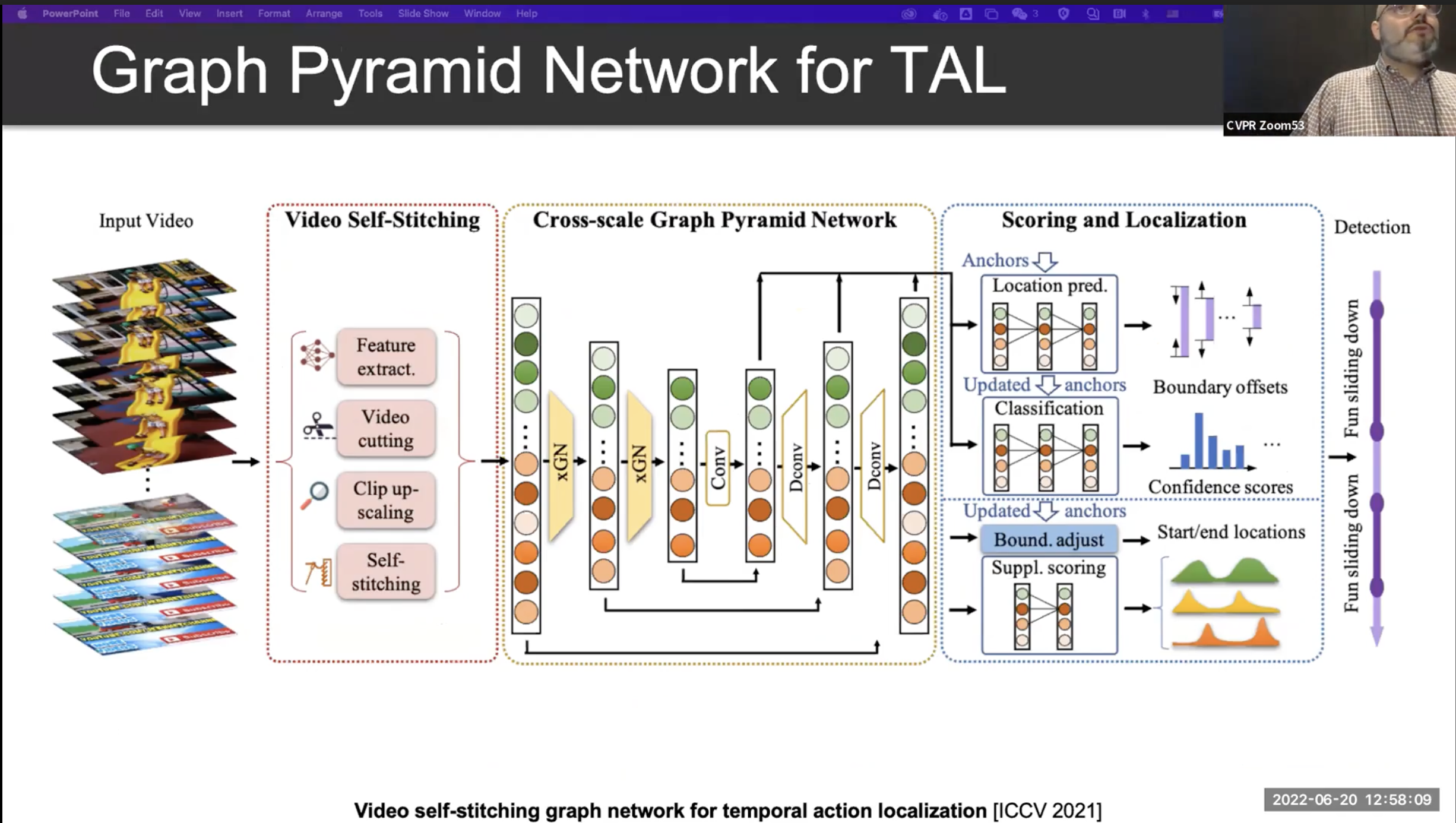
Multi Scale Localization
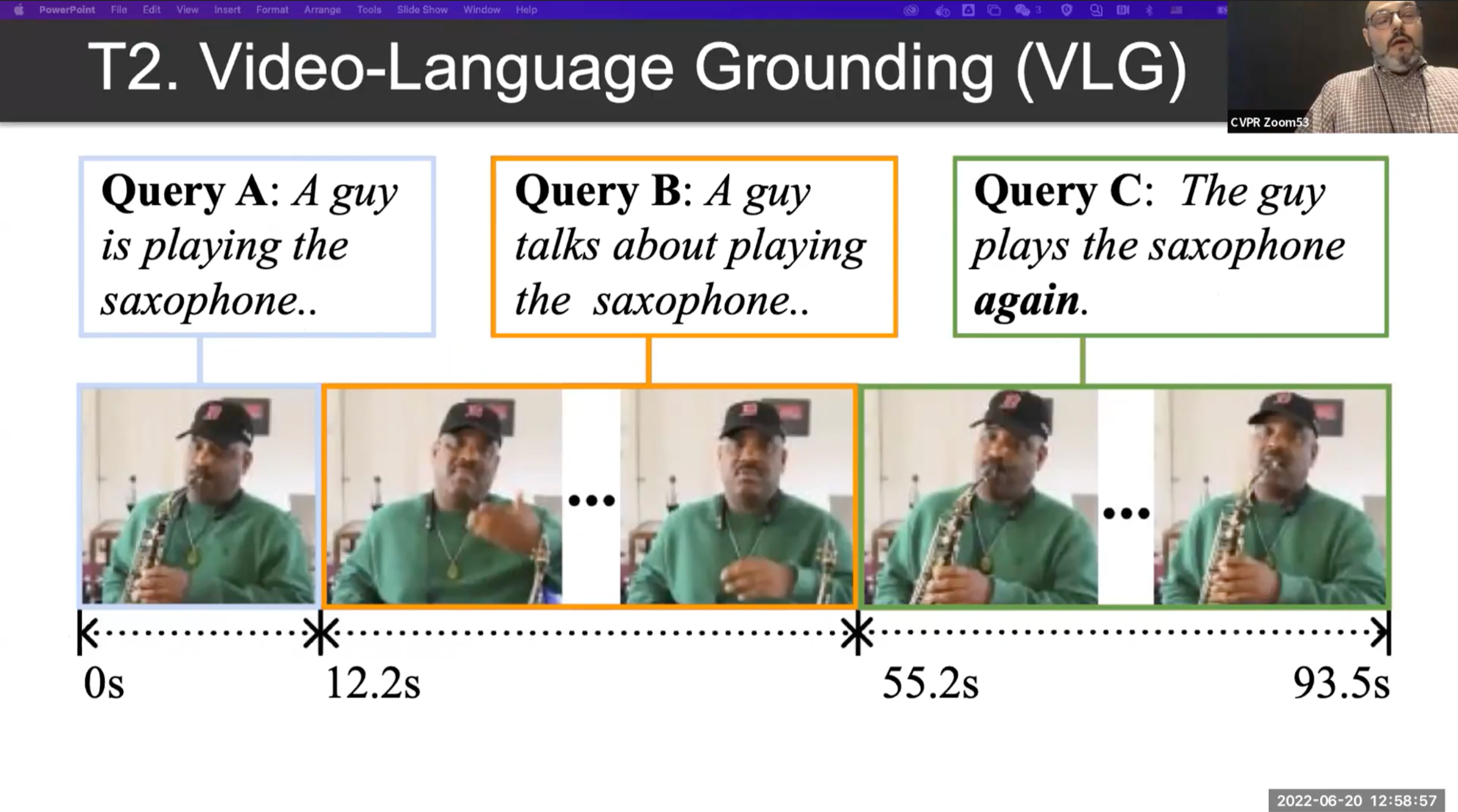
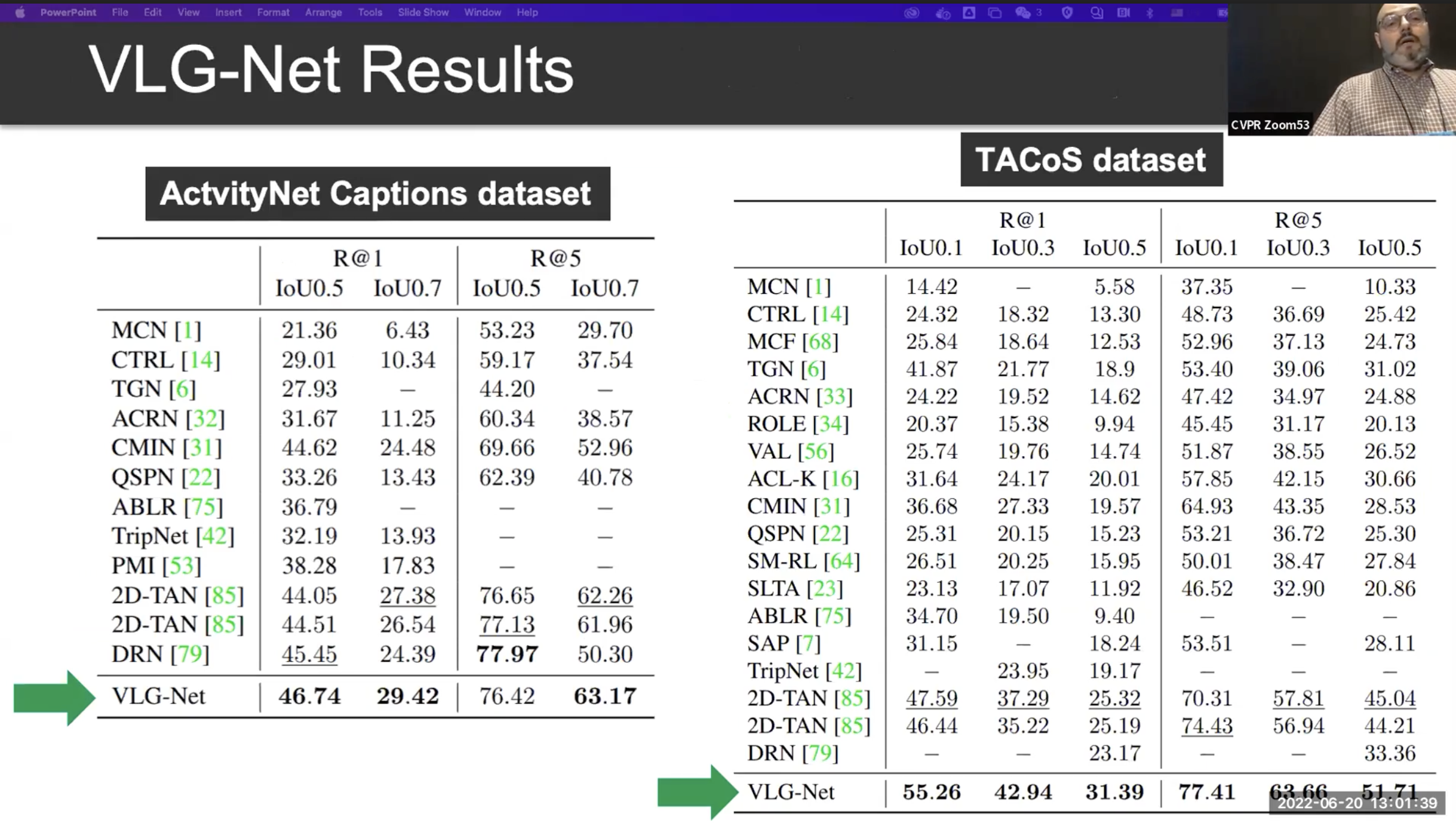
T2 : Video-Language Grounding (VLG)
VLG 과제는 비디오와 어떤 텍스트가 주어졌을때 해당하는 위치를 찾는 과제입니다.
아래의 예시를 자세히 보면, Query C 에는 again 이라는 단어가 추가 되었습니다. 언어적인 이해와 더불어 맥락적인 정보를 잘 이해할 수 있어야 합니다.
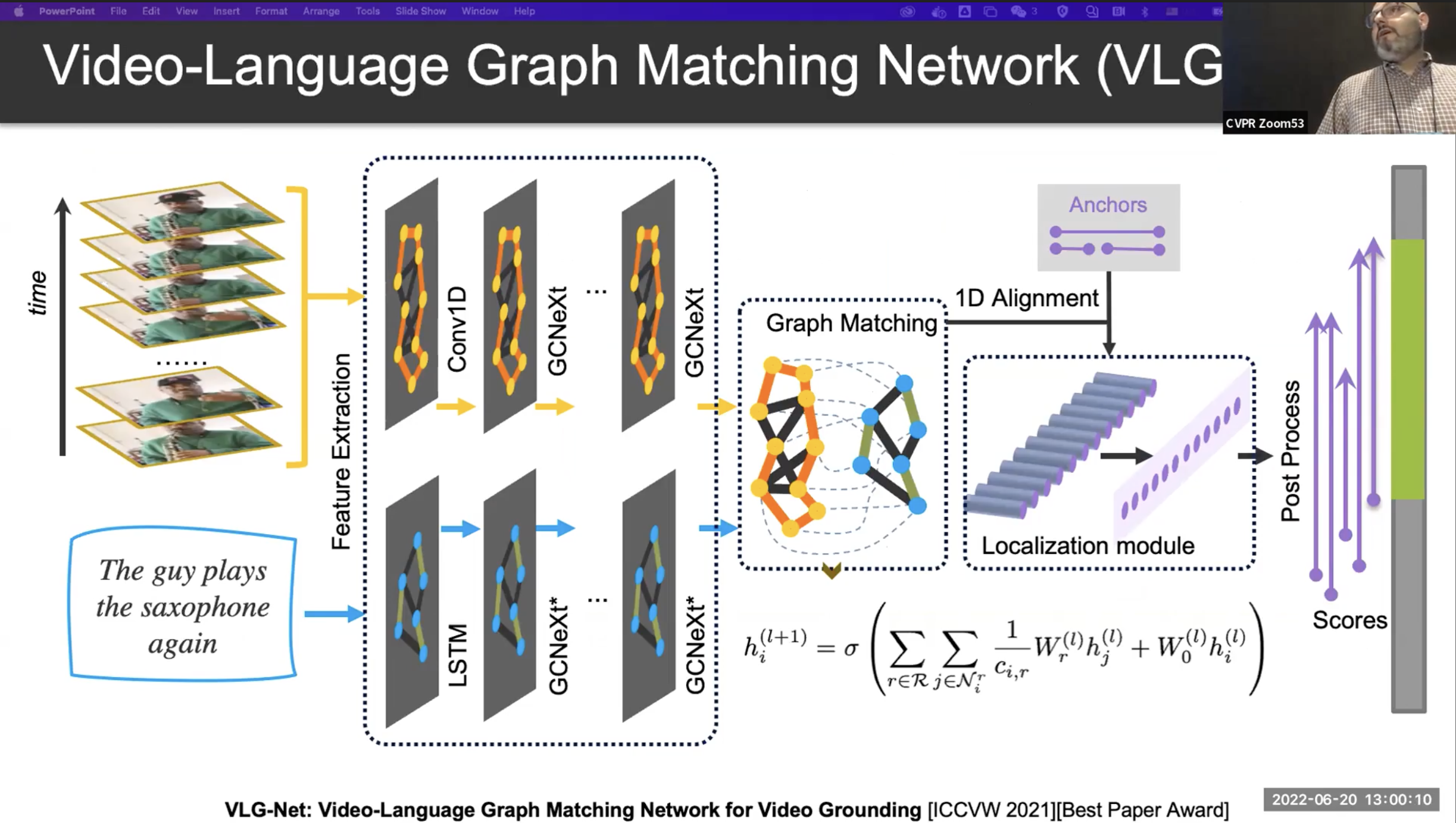
비디오 뿐만 아니라, 언어 텍스트에 대해서도 Graph Neura Network를 진행합니다. 이후 Graph Matching 알고리즘을 이용하여 언어와 동영상의 매칭을 완성합니다.
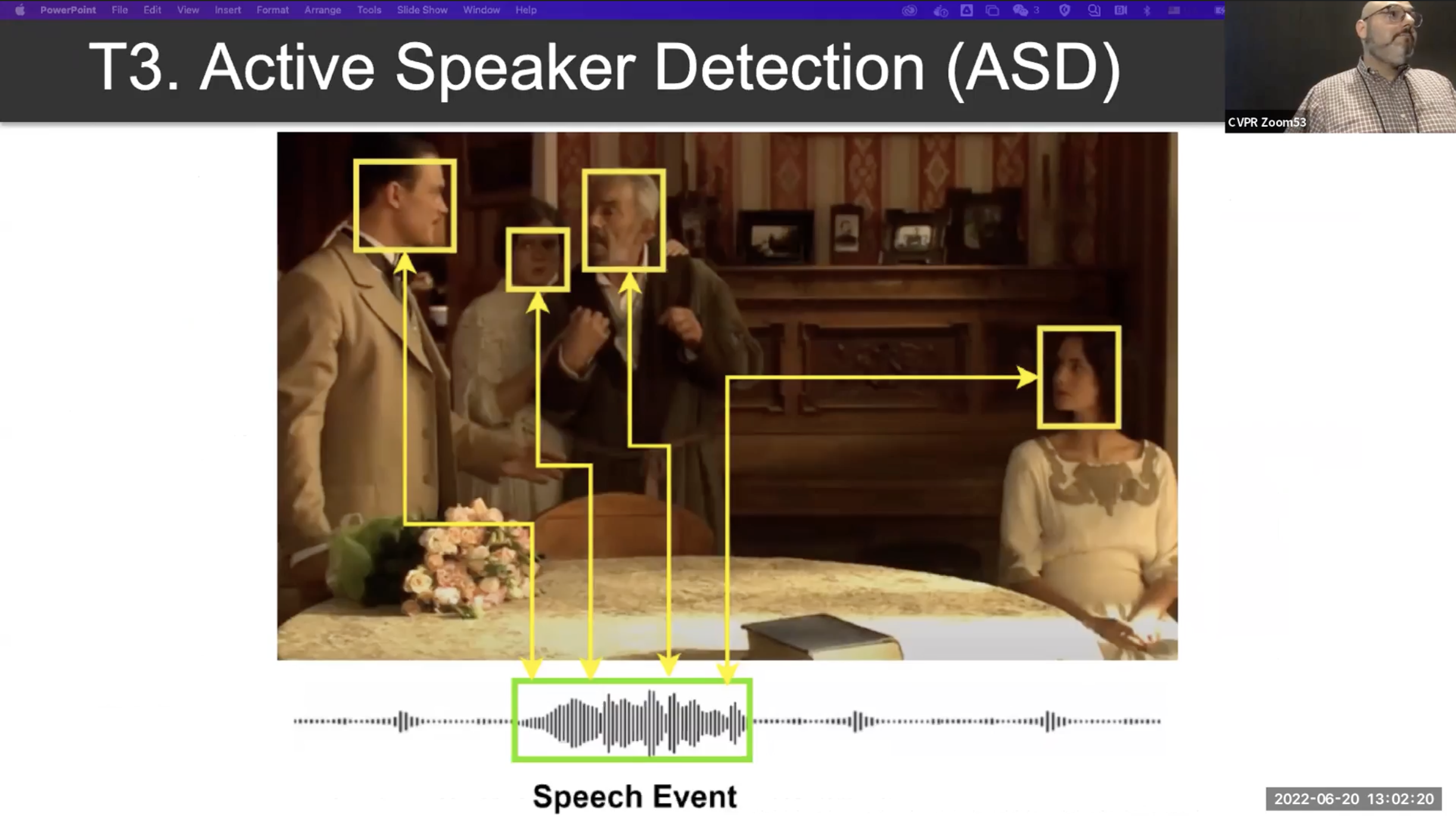
T3 : Active Speaker Detection (ASD)
비디오에서 언제 어디서 누가 말하고 있는지를 찾아내는 과제입니다.
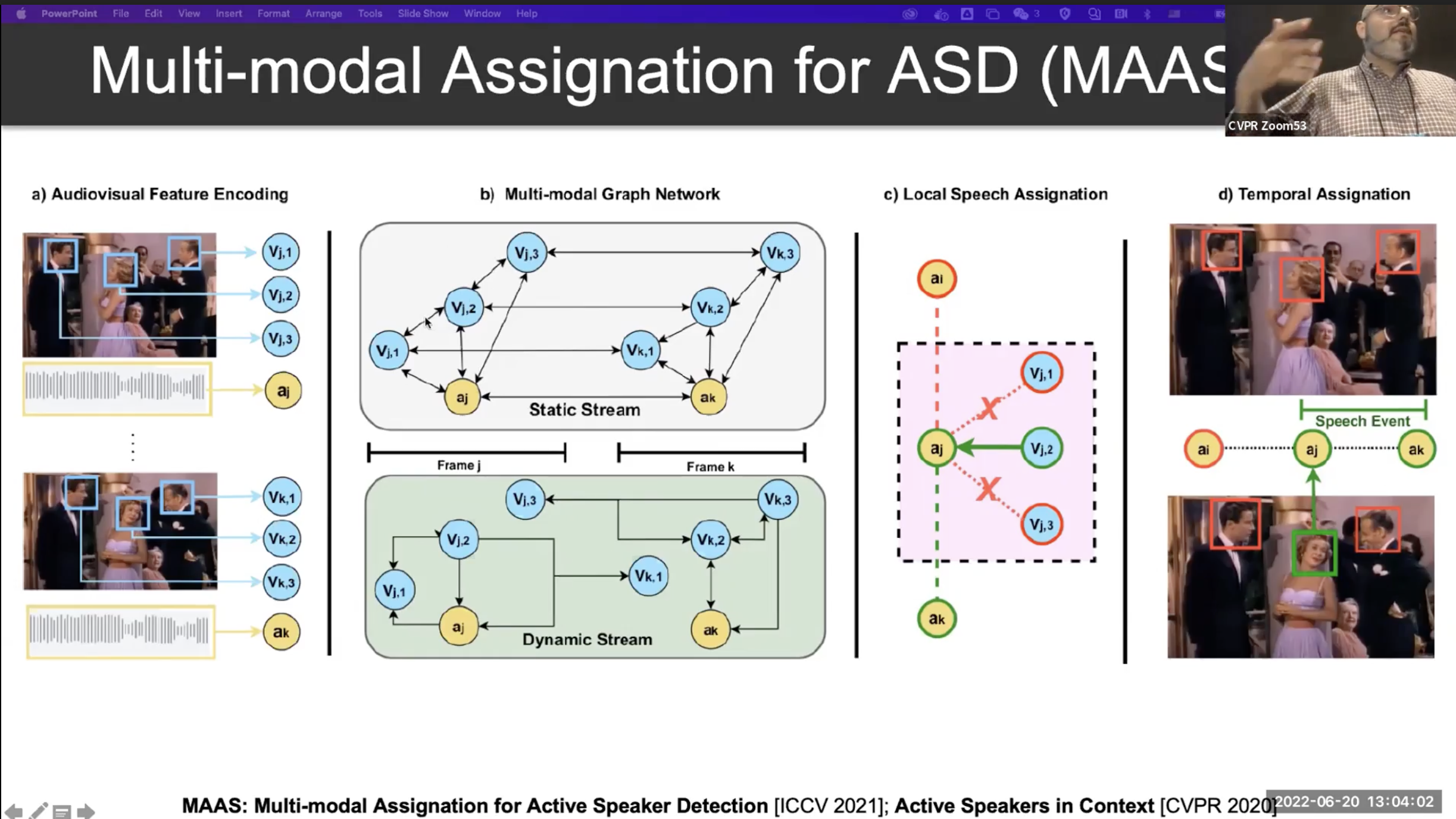
Conclusion
비디오 뿐만아니라 GNNs의 유연성을 통해 Multi-Modality 쪽으로 확장이 잘 되는 것 같습니다.
어렵네요 ㅋㅋ

'Artificial Intelligence > Neural Networks' 카테고리의 다른 글
| [ CVPR2022 / GML4VC ] 6. Deep GNNs (심층 그래프 신경망) 기본 개념 정리 (0) | 2022.08.25 |
|---|---|
| [ CVPR2022 / GML4VC ] 5. Pytorch Geometric 이란 무엇인가? (0) | 2022.08.24 |
| [ CVPR2022 / GML4VC ] 4. Graph Neural Networks(GNNS) 기본 개념 정리 (0) | 2022.08.24 |
| [ CVPR2022 / GML4VC ] 3. Geometric Deep Learning (Invariant, Equivariant) (1) | 2022.08.22 |
| [ CVPR2022 / GML4VC ] 2. Open Remarks (0) | 2022.08.22 |



