Confusion matrix, Classification Accuracy, Precision, Recall - (Popular Machine Learning Metrics)
이 글은 아래의 글을 바탕으로 쓰여졌습니다.
20 Popular Machine Learning Metrics. Part 1: Classification & Regression Evaluation Metrics
An introduction to the most important metrics for evaluating classification, regression, ranking, vision, NLP, and deep learning models.
towardsdatascience.com

Introduction
Machine learning(ML) models을 evaluate(평가)하기위해서는 올바른 metric을 선택하는 것이 매우 중요하다.
Application(상황)별 적절한 metric이 필요하다. 그러나 그 종류가 매우 많고 상황마다 쓰이는 metric이 다르기 때문에 이 글에서 통합적으로 정리하려고 한다.
20 metrics used for evaluating machine learning models
-
Classification Metrics (Accuracy, precision, recall, F1-score, ROC, AUC, ...)
-
Regression Metrics (MSE, MAE)
-
Ranking Metrics (MRR, DCG, NDCG)
-
Statistical Metrics (Correlation)
-
Computer Vision Metrics (PSNR, SSIM, IoU)
-
NLP Metrics (Perplexity, BLEU score)
-
Deep Learning Related Metrics (Inception score, Frechet Inception distance)
Side note : Metric vs. Loss function?
"Metric은 loss function과 다른 개념이다" 라는 사실을 알 필요가 있다.
처음 머신러닝을 접하는 사람들은 두 개념을 같다고 생각할 수 있는데 이 글을 통해 제대로 익히길 바란다.
Loss function은 model performance의 측정과 machine learning model을 학습시키기 위해서 사용되는 함수 이다. 다시말하면 최적화를 위해 사용되는 함수이다. 그렇기 때문에 모델의 parameters(매개변수)들이 미분 가능해야 한다.
반면에, Metrics의 경우 모델의 학습 또는 테스트 과정에서 model performance를 확인하고 평가만을 위해 사용되기 때문에 미분이 불가능해도 상관 없다.
몇몇 상황의 경우 미분가능한 Metrics(such as MSE)는 loss function으로 사용되기도 한다.

Classification Related Metrics
Classification은 머신러닝에서 가장 광범위하게 적용되는 문제중 하나이다. 얼굴인식, 유투브 비디오 범주화, 의료 진단 등 다양한 산업군에서 사용된다. Support vector machine (SVM), logistic regression, decision trees, random forest, XGboost, convolutional neural network¹, recurrent neural network 같은 모델들은 유명한 classification 모델들이다.
1 - Terminologies (not a metric, but important to know!)
각 metric을 설명하기에 앞서, classification 문제에서 사용되는 용어들에 대해서 알아보자.
Classification performance에서 중요한 개념중 하나는 confusion matrix(AKA error matrix)이다. 이는 모델의 예측과 실제 결과(ground-truth)를 비교하여 나타낸 표를 말한다. 각 가로행은 모델의 예측된 결과를 말하고 세로열을 실제 결과를 나타낸다.
아래의 예시를 통해 알아보자. 예를들어, 고양이(Cat)사진과 고양이가 아닌(Non-Cat) 사진을 구별해주는 binary classification 모델을 만든다고 가정하자. 여기서 test set 은 1100장의 사진인데 그 중에 1000장은 non-cat images, 나머지 100장은 cat images라고한다. 이때 아래의 confusion matrix를 보자.
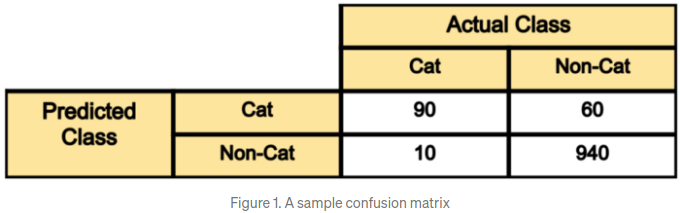
-
100장의 cat images중에 우리의 model은 90장을 정확히 판단했고, 나머지 10장을 잘못 판단했다.다시말하면, 100장의 고양이 사진중 90장을 고양이라고 판단했고(true-positive), 나머지 10장의 고양이사진을 고양이가 아니다라고 판단했다(false-negative)는 것을 알 수 있다.
-
1000장의 non-cat images중에 우리의 모델은 940장의 고양이가 아닌 사진을 정확히 고양이가 아니라고 판단했고(true-negative), 반대로 나머지 60장의 고양이가 아닌 사진을 고양이라고 판단했다(false-positive).
표의 대각선 요소들만 확인해보면, 90+940장의 이미지를 모델이 제대로 예측했다는 것이고, 반대 대각선 요소들을 확인해보면 60+10장의 이미지를 잘못 예측했다는 것이다.
2 - Classification Accuracy
Classification accuracy는 아마도 가장 단순한 metrics라고 생각한다. 단순히 전체 예측 개수중에 맞춘 예측 개수로 나누어 100을 곱한 것을 말한다. 흔히 말하는 얼마나 많이 맞췄냐만 생각하는 것이다. 위의 예시로 설명하자면, 1100개의 샘플중 1030개를 올바르게 예측했기 때문에 Classification accuracy 는 93.6%가 된다.
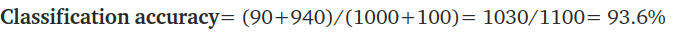
3 - Precision
허나 단순한 classification accuracy는 model performance의 좋은 지표가 아니다. 여러 예시 중 하나를 설명하자면, 표본의 class가 불균형한 상태(imbalanced class)를 생각해 보자. 구체적으로 의료 데이터를 예로 들어 병이 없는 정상 데이터가 전체의 98%이고 병이 있는 데이터가 2%라고 가정해보자. 여기서 단순히 모든 결과를 병이 없다고 모델이 예측했을때, classification accuracy는 98%라는 높은 성능을 나타낸다. 모델이 학습이 안되어도 예측을 정상입니다만 해도 98%의 classification Accuracy를 가지게 되는것이다.생각만 해도 끔찍하지 않은가?!
그러한 이유로 더 구체적인(specific) performance metrics에 대해서도 알아야 한다. Precision이 그런 metrics중 하나이다. 공식은 다음과 같다. 정답,오답은 모델의 예측에 대한 결과이고 yes,no는 모델의 예측이라고 할때,
▶ Precision = 정답(yes) / (정답(yes)+오답(yes)) = (모델이 맞춘 개수) / (모델이 cat이라고 예측한 개수)

위의 Cat & Non-Cat 문제에 대입해 보면 다음과 같은 결과를 가져온다.

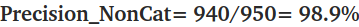
위의 결과를 정리하면, 우리의 모델이 고양이 사진이라고 판단했을때 정답일 경우가 60%라는 것이다.
반대로, 우리의 모델이 고양이가 아니라고 판단했을때 정답일 경우가 98.9% 라는 것이다.
다시한번 정리하자면, 모델이 고양이 사진이라고 판단하면 한번 의심해봐야한다. 정확도가 60%밖에 되지 않기 때문이다. 하지만 고양이가 아니라고 판단하면 98.9%로 꽤 믿을만하다.
놀라운가? 사실 그렇게 놀랍지도 않다. 왜냐하면 전체 데이터 개수를 봤을때, cat image는 100장밖에 없고, non-cat image는 1000장으로 훨씬 많다. non-cat에 대해서 훨씬 학습이 잘 되었기 때문이다.
4 - Recall
Recall은 또 다른 중요한 metric 중 하나이다. 이는 다음과 같이 나타낸다. 정답,오답은 모델의 예측에 대한 결과이고 yes,no는 모델의 예측이라고 할때,
▶ Recall = 정답(yes) / (정답(yes)+오답(no)) = (모델이 맞춘 개수) / (실제 cat 이미지의 개수)
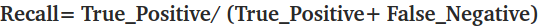
그래서 위의 예시 데이터로 Recall을 나타내면,
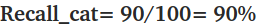
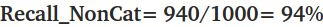
위의 결과를 정리하자면 실제 고양이 사진 100장 중에 90장을 고양이(90%)라고 판단했다.
반대로, 고양이가 아닌 사진 1000장 중에 940장을 고양이가 아니(94%)라고 판단했다.
Recall은 '재현율' 이라고도 불린다.
다음 글에서는 Classification Metrics인 F1-score, Sensitivity & Specificity, ROC Curve, AUC 등에 대해 다뤄 보겠다.
'Artificial Intelligence > Metrics' 카테고리의 다른 글
| [Metric/Object Detection] mAP(Mean Agerage Precision) (0) | 2021.12.23 |
|---|